This blog is the translation of my answer of this Chinese question:
Java NIO:
The DirectBuffer resides in user process address space or kernel?
InFileChannel#read(ByteBuffer dst),write(ByteBuffer src),if the class of parameter isHeapBuffer, it will allocate a tempDirectBufferto assist the read/write rather than using the parameterHeapBuffer, why?
User or Kernel
From ByteBuffer (Java Platform SE 8 ):
The contents of direct buffers may reside outside of the normal garbage-collected heap
The doc tells us that the direct buffer may reside outside heap, and that means this is rely on JVM implementation, which is not coerced by JLS.
Back to the question, if the direct buffer resides outside of heap, does it belongs to user or kernel?
First, we all know every process has its own address space (virtual address), i.e. for a Java process, it can only read/write its own memory. But, kernel is different. It has a global view: it can read/write all physical address, which includes all virtual address space. (If you are interested in details, you may would like to refer to my simple linux-like os implementation).
So from this point of view, DirectBuffer belongs to that Java process, but also belongs to kernel.
A Temp DirectBuffer
Cited from Ron Hitches Java NIO:
In the JVM, an array of bytes may not be stored contiguously in memory, or the Garbage Collector could move it at any time. Arrays are objects in Java, and the way data is stored inside that object could vary from one JVM implementation to another.
For this reason, the notion of a direct buffer was introduced. Direct buffers are intended for interaction with channels and native I/O routines. They make a best effort to store the byte elements in a memory area that a channel can use for direct, or raw, access by using native code to tell the operating system to drain or fill the memory area directly.
Direct byte buffers are usually the best choice for I/O operations. By design, they support the most efficient I/O mechanism available to the JVM. Nondirect byte buffers can be passed to channels, but doing so may incur a performance penalty. It’s usually not possible for a nondirect buffer to be the target of a native I/O operation. If you pass a nondirect ByteBuffer object to a channel for write, the channel may implicitly do the following on each call:
- Create a temporary direct ByteBuffer object.
- Copy the content of the nondirect buffer to the temporary buffer.
- Perform the low-level I/O operation using the temporary buffer.
- The temporary buffer object goes out of scope and is eventually garbage collected.
In Short:
The OS like to manipulate a continuous area of memory for IO operation (Why? e.g. the minimal read unit for disk is 512B. If the application just read one byte, most of time is wasted; addressing in memory also takes some time), but in JVM:
- Byte array is not necessarily adjacent (note: in JLS chapter 10 Arrays, there is no requirement that array element have to be adjacent, so author said that. But, in real implementations, I guess, no JVM will split array element.);
- GC may move the array around;
- Different JVM may have different implementations of array, which may have different structure;
So, JVM introduce DirectBuffer to deal with upper problems.
And author said:
It’s usually not possible for a nondirect buffer to be the target of a native I/O operation.
But why?
Non-DirectBuffer must resides in heap of JVM, and its life cycle is managed by GC. GC algorithms has two main kinds:
- mark and copying – used in most eden area;
- mark and compact – used in old area of Serial/Parallel GC;
- mark and sweep – used in old area of CMS;
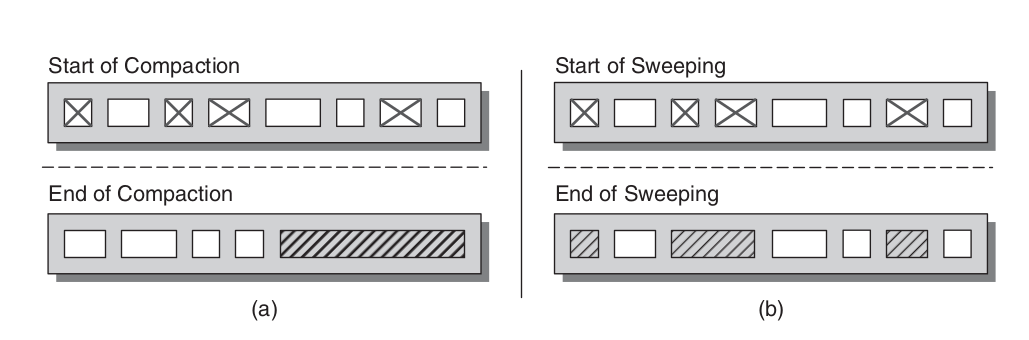
So using Non-DirectBuffer will cause more work of GC, because:
- mark: in the mark phase, using a JNI referred byte array will cause more work
- compact: if the algo is compcation:
- need to move byte array:
- which should update the address of byte array in JNI
- which should stop IO operation
- or pin the byte array, not move that part
- or not GC when IO (which is not possible for it may cause OOM)
- need to move byte array:
So ByteBuffer document (Java Platform SE 8 ) says:
Given a direct byte buffer, the Java virtual machine will make a best effort to perform native I/O operations directly upon it. That is, it will attempt to avoid copying the buffer’s content to (or from) an intermediate buffer before (or after) each invocation of one of the underlying operating system’s native I/O operations.
In other words, even FileChannel doesn’t make a temp array, the JVM may still need copy content to intermediate buffer, which is even slower. And DirectBuffer is managed by JVM, which is easy to optimize and reuse.
Conclusion
In conclusion, all of above content are analysis in theory, you need to test to choose the right way. Conclude with that famous saying:
First make it right, then make it fast.
这篇博客来自于我在这个问题的答案
DirectBuffer 属于堆外存,那应该还是属于用户内存,而不是内核内存?
来自 ByteBuffer (Java Platform SE 8 )
The contents of direct buffers may reside outside of the normal garbage-collected heap
所以DirectBuffer是否真的是堆外存并不是强制的,是依赖JVM实现的。
回归正题:DirectBuffer属于用户内存还是内核内存?
首先,我们知道,每个进程是有独立的地址空间的,也就是说对于一个Java进程来说,他只能看到自己的内存,他只能读写自己的内存。而内核其实是有上帝视角的,如早期的linux,内核是能看到并读写所有物理内存的(关于这一点,有兴趣的可以参看我的简写版linux的实现:kvm.c)。
所以从这个角度上讲,DirectBuffer只是那个Java 进程的内存,但是对于内核来说,他也是能看到并读写的。所以到底属于谁,这个问题本身有点模糊。
FileChannel 的read(ByteBuffer dst)函数,write(ByteBuffer src)函数中,如果传入的参数是HeapBuffer类型,则会临时申请一块DirectBuffer,进行数据拷贝,而不是直接进行数据传输,这是出于什么原因?
Ron Hitches Java NIO:
In the JVM, an array of bytes may not be stored contiguously in memory, or the Garbage Collector could move it at any time. Arrays are objects in Java, and the way data is stored inside that object could vary from one JVM implementation to another.
For this reason, the notion of a direct buffer was introduced. Direct buffers are intended for interaction with channels and native I/O routines. They make a best effort to store the byte elements in a memory area that a channel can use for direct, or raw, access by using native code to tell the operating system to drain or fill the memory area directly.
Direct byte buffers are usually the best choice for I/O operations. By design, they support the most efficient I/O mechanism available to the JVM. Nondirect byte buffers can be passed to channels, but doing so may incur a performance penalty. It's usually not possible for a nondirect buffer to be the target of a native I/O operation. If you pass a nondirect ByteBuffer object to a channel for write, the channel may implicitly do the following on each call:
1. Create a temporary direct ByteBuffer object.
2. Copy the content of the nondirect buffer to the temporary buffer.
3. Perform the low-level I/O operation using the temporary buffer.
4. The temporary buffer object goes out of scope and is eventually garbage collected.
翻译一下:
操作系统通常喜欢一次读很多并且一整块内存进行io操作(为什么?比如对于硬盘来说,最小的读取单位是512B,如果应用只读一个byte的话,是不是很浪费–这也是旧的IO包比较慢的一个原因;内存寻址也是要时间,所以连续内存就会比random access要快),但是在JVM中:
- byte数组不一定连续
- GC会移动数组
- 数组实现在不同JVM中可能会不同
所以在JVM中引入DirectBuffer用于解决如上问题。
书中说 “一般来说,Non-DirectBuffer是不适合用于native的IO”, 所以需要复制。但是为什么Non-DirectBuffer不适合呢?
Non-DirectBuffer肯定是JVM heap中的,所以他肯定是要归GC管理的。GC算法有两个流派
mark and copying -- 新生代常用算法
mark and compact -- 老年代常用算法,Serial GC, Parallel GC
mark and sweep -- 老年代常用算法,CMS
所以使用Non-DirectBuffer必然导致GC更多的工作:
- mark:不管是mark-and-compact 还是mark-and-swap,使用一个JNI引用的buffer(因为IO操作是JNI实现的,所以IO routine是会),都是会引起GC的mark阶段更多的工作
- compact:毋庸置疑,如果Non-DirectBuffer是使用compaction方式
- 需要在gc之后移动byte array。这样的话(很复杂):
- 需要更新JNI那里的byte array地址
- 需要暂停IO
- 或者如学长所说,pin住byte array
- 或者是在IO时,不要进行GC(显然是不合适的,如果IO时间比较长,heap岂不是要out of memory)
- 需要在gc之后移动byte array。这样的话(很复杂):
所以 ByteBuffer (Java Platform SE 8 ) 才会说:
Given a direct byte buffer, the Java virtual machine will make a best effort to perform native I/O operations directly upon it. That is, it will attempt to avoid copying the buffer's content to (or from) an intermediate buffer before (or after) each invocation of one of the underlying operating system's native I/O operations.
也就是说,即使FileChannel#read中不进行复制,JVM中的其它地方也是可能复制的,所以这样在很多情况下是有效率优势的。并且directBuffer由于是JVM直接管理的,使得它可以轻松的优化和复用。
Ref
Written with StackEdit.
Emm,when execute method: channel.write(DirectByteBuffer).Date of DirectByteBuffer need to copy from user spaceto kernel space?
回复删除Data of DirectByteBuffer
删除