LevelDB “is an open source on-disk key-value store.”
After I read some documents, I have some basic understanding of LevelDB. So I come up with some questions about structure of LevelDB to answer when reading the source code.
Structure
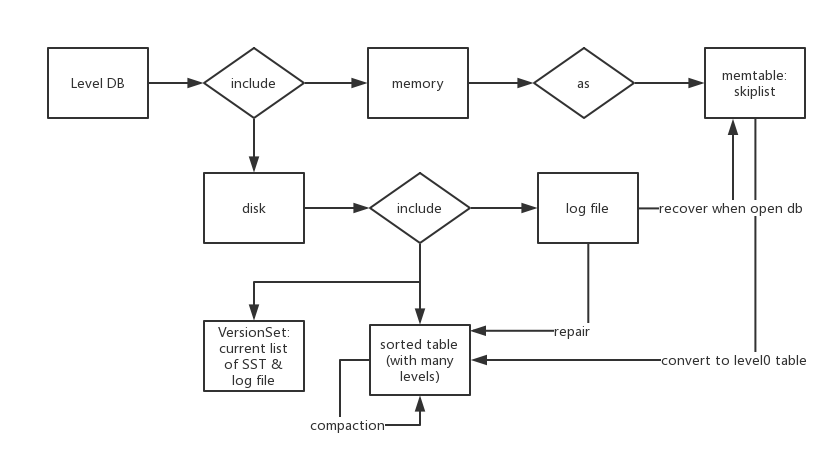
Log File: repair/recover db
A log file (*.log) stores a sequence of recent updates. Each update is appended to the current log file.
The log file contents are a sequence of 32KB blocks. The only exception is that the tail of the file may contain a partial block.
Block format:
Each block consists of a sequence of records:
block := record* trailer?
record :=
checksum: uint32 // crc32c of type and data[] ; little-endian
length: uint16 // little-endian
type: uint8 // One of FULL, FIRST, MIDDLE, LAST
data: uint8[length] // data is LengthPrefixedSlice with type from batch
data definition in Block:
data: also named `writeBatch` in levelDB
// WriteBatch header has an 8-byte sequence number followed by a 4-byte count.
--------------------------------------------------
sequence | |key/value | |
number | count | kType | depend | | kType |
| | on kType |... |
--------------------------------------------------
// WriteBatch::rep_ :=
// sequence: fixed64
// count: fixed32
// data: record[count]
// record :=
// kTypeValue varstring varstring |
// kTypeDeletion varstring
// varstring :=
// len: varint32
// data: uint8[len]
Code example to generate WriteBatch when put data & delete data:
//write_batch.cc
void WriteBatch::Put(const Slice& key, const Slice& value) {
WriteBatchInternal::SetCount(this, WriteBatchInternal::Count(this) + 1);
rep_.push_back(static_cast<char>(kTypeValue));
PutLengthPrefixedSlice(&rep_, key);
PutLengthPrefixedSlice(&rep_, value);
}
void WriteBatch::Delete(const Slice& key) {
WriteBatchInternal::SetCount(this, WriteBatchInternal::Count(this) + 1);
rep_.push_back(static_cast<char>(kTypeDeletion));
PutLengthPrefixedSlice(&rep_, key);
}
- What the log file is for? Used in recover at start up:
Status VersionSet::Recover(bool *save_manifest) {
//...
log::Reader reader(file, &reporter, true/*checksum*/, 0/*initial_offset*/);
Slice record;
std::string scratch;
while (reader.ReadRecord(&record, &scratch) && s.ok()) {...}
- What is
SequenceNumberfor? As the following comment says, it is used to compose the real key:
//dbformat.h
// make up of the internalKey to store and lookup
// user_key + (sequence << 8) | value
InternalKey(const Slice& user_key, SequenceNumber s, ValueType t) {
// used when searching in memtable
LookupKey(const Slice& user_key, SequenceNumber sequence);
struct ParsedInternalKey {
Slice user_key;
SequenceNumber sequence;
ValueType type;
// ...
};
- What is deletion marker – kTypeDeletion
A sorted table (*.sst) stores a sequence of entries sorted by key. Each entry is either a value for the key, or a deletion marker for the key. (Deletion markers are kept around to hide obsolete values present in older sorted tables).
Compactions drop overwritten values. They also drop deletion markers if there are no higher numbered levels that contain a file whose range overlaps the current key.
Sorted table
// A Table is a sorted map from strings to strings. Tables are
// immutable and persistent. A Table may be safely accessed from
// multiple threads without external synchronization.
class Table {}
A sorted table (*.sst) stores a sequence of entries sorted by key. Each entry is either a value for the key, or a deletion marker for the key.
- How is key stored in sorted table?
// File format contains a sequence of blocks where each block has:
// block_data: uint8[n]
// type: uint8 -- compression type
// crc: uint32
// block_builder.cc: block format
// When we store a key, we drop the prefix shared with the previous
// string. This helps reduce the space requirement significantly.
// Furthermore, once every K keys, we do not apply the prefix
// compression and store the entire key. We call this a "restart
// point". The tail end of the block stores the offsets of all of the
// restart points, and can be used to do a binary search when looking
// for a particular key. Values are stored as-is (without compression)
// immediately following the corresponding key.
//
// An entry for a particular key-value pair has the form:
// shared_bytes: varint32
// unshared_bytes: varint32
// value_length: varint32
// key_delta: char[unshared_bytes]
// value: char[value_length]
// shared_bytes == 0 for restart points.
//
// The trailer of the block has the form:
// restarts: uint32[num_restarts]
// num_restarts: uint32
// restarts[i] contains the offset within the block of the ith restart point.
void BlockBuilder::Add(const Slice& key, const Slice& value) {}
- How is key found in sorted table? file binary search?
Yes, as above comment says.
// The tail end of the block stores the offsets of all of the
// restart points, and can be used to do a binary search when looking
// for a particular key.
// db_impl.c
// First look in the memtable, then in the immutable memtable (if any).
LookupKey lkey(key, snapshot);
if (mem->Get(lkey, value, &s)) {
// Done
} else if (imm != NULL && imm->Get(lkey, value, &s)) {
// Done
} else {
s = current->Get(options, lkey, value, &stats);
have_stat_update = true;
}
// version_set.cc
// Binary search to find earliest index whose largest key >= ikey.
uint32_t index = FindFile(vset_->icmp_, files_[level], ikey);
- Index format detail
[meta block 1]
...
[meta block K]
[metaindex block]
[index block]
[Footer] (fixed size; starts at file_size - sizeof(Footer))
// table_builder.cc: TableBuilder::Add, Flush, Finish
// add an index entry after every flush, i.e. finish a block
if (r->pending_index_entry) {
assert(r->data_block.empty());
r->options.comparator->FindShortestSeparator(&r->last_key, key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
// mapping [string key => offset/size]
Memtable
- The structure of memtable? – skiplist
// memtable.h
typedef SkipList<const char*, KeyComparator> Table;
KeyComparator comparator_;
int refs_;
Arena arena_;
Table table_;
explicit MemTable(const InternalKeyComparator& comparator);
// dbformat.cc
// Order by:
// increasing user key (according to user-supplied comparator)
// decreasing sequence number
// decreasing type (though sequence# should be enough to disambiguate)
- Contents in node of skiplist
// -----------
// key+`(sequence << 8) | ktype` | value
// -----------
// entry format is:
// klength varint32
// userkey char[klength]
// tag uint64
// vlength varint32
// value char[vlength]
- What is
Arena?
// Create a new SkipList object that will use "cmp" for comparing keys,
// and will allocate memory using "*arena". Objects allocated in the arena
// must remain allocated for the lifetime of the skiplist object.
explicit SkipList(Comparator cmp, Arena* arena);
The Arena class provide a rapid C/C++ allocation layer that sits on top of the C/C++ malloc/free memory management routines. It is the memory pool which is commonly used to optimize the performance of your software.
static const int kBlockSize = 4096;
if (bytes > kBlockSize / 4) {
// Object is more than a quarter of our block size. Allocate it separately
// to avoid wasting too much space in leftover bytes.
char* result = AllocateNewBlock(bytes);
return result;
}
// We waste the remaining space in the current block.
alloc_ptr_ = AllocateNewBlock(kBlockSize);
alloc_bytes_remaining_ = kBlockSize;
- What is relationship between memtable and immutable memtable ?
if (mem->Get(lkey, value, &s)) {
// Done
} else if (imm != NULL && imm->Get(lkey, value, &s)) {
// Done
} ...
// extract sequence and kType to insert memtable
status = WriteBatchInternal::InsertInto(updates, mem_);
// Attempt to switch to a new memtable and trigger compaction of old
imm_ = mem_;
// then compact imm_
MaybeScheduleCompaction();
In conclusion, memtable is newer version, so preferred for reading/writing, and immutable memtable is older version for compaction
Ref
- Latency Numbers Every Programmer Should Know
- The git repo I forked and add some comments to help reading
- sstable and log structured storage leveldb
Written with StackEdit.
评论
发表评论